Spark

Spark 란 빅데이터 처리를 위한 클러스터용 병렬 분산처리 플랫폼이다.
Why we use Spark?
MapReduce와 Dryad 등은 대규모 데이터 분석을 용이하게 만들었지만 반복 알고리즘이나, 대화형 마이닝 툴과 같은 어플 리케이션의 경우에는 상당히 비효율적이었다. 왜냐하면 MapReduce와 같은 경우에는 Fault-Tolerance를 위해 중간 데이터를 storage에 쓰게 되는데, 반복 알고리즘의 경우 이 중간 값을 다시 input으로 반복해서 사용하기 때문에 Disk I/O와 직렬 화 등으로 인한 overhead가 비교적으로 크게 발생하기 때문이다.
Hadoop을 기반으로 한 MapReduce의 단점이다.
- disk로 많은 I/O가 발생하기 때문에, 그만큼 trade-off가 발생할 수 있다.
- 연산이 시작되면, 중간에 값을 확인하지 못한다. non-interactive 하다.
- serialization 때문에 연산 속도가 느리다.
- iteration job에 취약하다. (replication, serialization, disk I/O 모두 해당)
- MapReduce 동작 구조 : HDFS는 replication을 가지기 때문에, iteration을 하려면 HDFS에 계속 저장을 해야하기 때문에 Disk I/O가 여기서 발생하며 늦어진다.
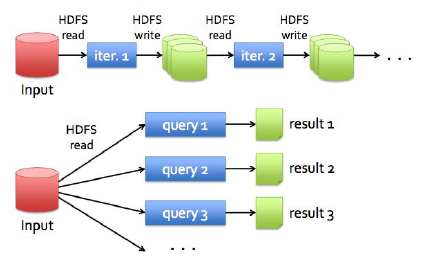
이 overhead를 줄이기 위해 제안한 방법이 중간 결과값 을 메모리에 올리는 방법이었으나 메모리는 휘발성이기 때문에 장애가 발생했을때 Fault-Tolerance를 유지하기 어려웠다. Twister나 Haloop처럼 반복 알고리즘을 위한 방법들이 제안되었으나 모두 MapReduce에 제한된 것이 한계였다.
따라서 이 단점을 보완하기위해 Spark가 나왔다.
What is the purpose of Spark?
- More Complex, multi-pass analytics (1대의 서버가 복수의 패스를 통해 스토리지 장치에 접속하는 방법)
- More Interactive, ad-hoc queries (sql문이 바로 바로 생성되서 쿼리문을 적용 가능)
- More Real-time, Streaming Processing (중간 결과물을 확인 가능, streaming 처럼)
- RDD의 기존 MapReduce의 장점을 유지하면서 중간 결과값을 효율적으로 재사용하는 것(지금까지는 intermediate를 disk에 저장해서 매우 느렸지만, Fault-Tolerance는 보장되었다.)
따라서 Spark는 in disk가 아니라, in Memory를 선택한다. In-Memory system을 가지고 있기 때문에, HDFS 기반에서 동작하는 MapReduce 보다 훨씬 빠르다.

지금까지는 intermediate를 disk에 저장해서 매우 느렸지만, Fault-Tolerance는 보장되었다.
따라서 RDD도 Fault-Tolerance를 보장하되, intermediate를 disk에 저장하지 않고 새로운 방법을 도색하는데,
- Checkpointing : 이는 중간 결과값을 intermediate에 일정 시간이 지나면, 넣는 형식이니 똑같이 disk I/O 가 발생.
- Logging up update : logging 데이터가 똑같이 커지면 Disk I/O가 발생한다.
따라서 RDD는 중간결과값을 생성할 수 있는 작업목록만을 저장하여, 장애가 발생했을때 이 작업목록을 이용하여 중간 결과값을 다시 재생산하는 방식을 사용한다. -> 만약 fail이 발견될 경우, 중간결과값을 내는 목록들을 다시 만들어서 다시 연산을 진행한다.
RDDs (Resilient Distributed Datasets)
정의
RDD는 <클러스터들을 통합하여 메모리에 있는 부분을 cache하는 객체들의 분산된 collection>들을 말한다.
즉, 우리는 Spark 연산이 메모리에 있는 부분을 cache 해서 이미 속도가 빠른 객체들의 collection에 연산을 시킨다.
특징
- immutable, 바뀌지 않는다. (read-only) -> iteration에 최적화
- partitioned collections of records,
- Python, Java, Scala 지원
- code

RDD internal interface

- partitions() : Partition object 들이 담긴 list를 return
- preferredLocations(p) : partition 인 p 가 data locality 때문에 더욱 빠르게 접근할 수 있는 node들의 list
- dependencies() : dependencies의 list들을 return
- iterator(p, parentIters)
- partitioner() : RDD가 hash/range partitoned 되어있든지, 일단 metadata들을 return 한다.
Transformation (중요!)
우리가 'action'을 취하면, "Lazy Evalution"을 통해 새롭게 바뀌는 RDD다.
이는 우리가 RDD 객체를 만들어서 data를 input 할 텐데, 이 때 action을 취해야, action을 취한거에서 제일 최적화해서
RDD를 배치 후, action을 취한다. 이러한 동작, 최적화 때문에 연산이 다른 MapReduce 보다 월등히 빠르다.
Actions
RDD연산의 두 번째 시작점이다. 이들은 final value를 driver program 이나 다른 외부 저장 시스템에 data를 쓴다.
How to efficiently perform these functions in Spark?
Lazy Evaluation
Lazy Evaluation은 RDD의 Transformation을 바로 진행하지 않고, Transformation을 어떻게 배치해야 효율적일까를 고민하고, 최적화를 한다. 따라서 spark가 연산을 요구하는 action이 취해지면 진행한다.
즉, Transformation은 setting, Action은 performing function을 담당한다고 보자.!!!!
이를 통해 cost optimal을 한다.

Spark Component

Driver
Driver는 너의 program의 main method가 돌아가는 process, 실행공간이다.
이 process는 SparkContext를 생성, RDD를 생성, 정의, Transformation 과 action을 수행한다.
Executor
Spark Executor는 개인 task를 실행하는 역할을 맡는다. 또한 RAM의 RDD 파티션을 Java 개체로 캐시할 수 있는 프로세스다.
Executor들은 Spark가 시작될 때, 한 번 실행되며, application이 꺼지기 전까지 유지된다.
하지만 executor가 fail 한다하더라도, Spark는 여전히 실행된다.
Driver와 Executor는 초기에 어떻게 실행되나?
Spark는 cluster manager에 의존한다. manager는 Spark에 붙일 수 있다.
또한 Spark는 외부의 manager인 YARN, Mesos를 붙일 수 있다.
'대학원 공부 > computer science' 카테고리의 다른 글
| Spark : File format, Compression, File System, Accumulator (0) | 2019.12.19 |
|---|---|
| Spark : Partitioning (0) | 2019.12.18 |
| Network : Transport Layer, UDP, TCP (0) | 2019.12.17 |
| Network : Network Layer : Internet Protocol (0) | 2019.12.17 |
| Network : Application Layer (0) | 2019.12.16 |




댓글