자연어처리 : Tagging Work
정의
태깅작업이란? 단어에 어떠한 종류의 단어인지, tagging을 하는 작업을 말한다.
개체명 인식기와 품사 태거를 만드는데, 이러한 두 작업의 공통점은 RNN의 다-대-다(Many-to-Many) 작업이면서 또한 앞, 뒤 시점의 입력을 모두 참고하는 양방향 RNN(Bidirectional RNN)을 사용한다는 점이다.
1. training data에 대한 이해
X와 y데이터의 쌍(pair)은 병렬 구조를 가진다는 특징을 가집니다. X와 y의 각 데이터의 길이는 같습니다.
| ['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb'] | ['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O'] | 8 (데이터의 길이) | |
| 1 | ['peter', 'blackburn'] | ['B-PER', 'I-PER'] | 2 |
| 2 | ['brussels', '1996-08-22' ] | ['B-LOC', 'O'] | 2 |
| 3 | ['The', 'European', 'Commission'] | ['O', 'B-ORG', 'I-ORG'] | 3 |
X_train[3]의 'The'와 y_train[3]의 'O'는 하나의 쌍(pair)입니다. 또한, X_train[3]의 'European'과 y_train[3]의 'B-ORG'는 쌍의 관계를 가지며, X_train[3]의 'Commision'과 y_train[3]의 'I-ORG'는 쌍의 관계를 가진다.
이렇게 병렬 관계를 가지는 각 데이터는 " 각자 나타내는 단어에 대한 "정수 인코딩 과정을 거친 후,
모든 데이터의 길이를 동일하게 맞춰주기위한 패딩(Padding) 작업을 거친다.
2. 시퀀스 레이블링(Sequence Labeling)
위와 같이 입력 시퀀스 X = [x1, x2, x3, ..., xn] --> 레이블 시퀀스 y = [y1, y2, y3, ..., yn]를 각각 부여하는 작업을 시퀀스 레이블링 작업(Sequence Labeling Task)이라고 합니다. 태깅 작업은 대표적인 시퀀스 레이블링 작업입니다.
3. 양방향 LSTM(Bidirectional LSTM)
model.add(Bidirectional(LSTM(hidden_size, return_sequences=True)))텍스트 분류 챕터에서는 단방향 LSTM을 사용하였지만, 이번 챕터에서는 양방향 LSTM을 사용한다.
이전 시점의 단어 정보 뿐만 아니라, 다음 시점의 단어 정보도 참고하기 위함입니다. .
양방향은 기존의 단방향 LSTM()을 Bidirectional() 안에 넣으면 된다.
인자 정보는 단방향 LSTM을 사용할 때와 동일하다. 즉, 인자값을 하나를 줄 경우에는 이는 hidden_size를 의미하며, 결과적으로 output_dim이 된다.
4. RNN의 다-대-다(Many-to-Many) 문제
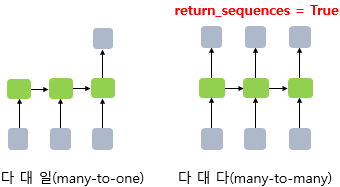
기존 RNN의 은닉층은 모든 시점에 대해서 은닉 상태값을 출력할 수 있고 <다 대 다>, 반대로 마지막 시점에 대해서만 은닉 상태값을 출력할 수 있다 <다 대 일>. 이는 인자로 return_sequences=True를 넣을 것인지, 넣지 않을 것인지로 설정할 수 있는데 태깅 작업의 경우에는 다-대-다(Many-to-Many) 문제로 return_sequences=True를 설정하여 출력층에 모든 은닉 상태값을 보내야한다.
예시 - 1

하지만 이번 실습에서는 양방향 RNN을 사용할 것이므로 아래의 그림과 같다.
