Linear Discriminant Analysis (LDA)
배경


data가 특정 범주로 나눠질 때, 이를 선을 그어서 model을 만드는 것을 LDA라고 한다.
가정
- 각 숫자 집단은 "정규분포 형태의 확률분포"를 가진다. (μ, σ를 써야하기 때문에)
- 각 숫자 집단은 "비슷한 형태의 공분산 구조"를 가진다.
특징
- Boundary Plane에 직교하는 단위벡터 : 자료들을 이 단위벡터에 정사영 시킨 분포의 형태를 고려.
- 평균의 차이를 극대화하려면? : 두 평균 vector (μ1 - μ2) 의 차이 벡터를 이용.
- 분산대비 평균의 차이를 극대화 하는 boundary를 찾는 것이 목표
정의

LDA의 확률모델은 log( fk(x)/ fl(x) ) + log(πk/πl) 이고, 0보다 크면 범주 k, 0보다 작으면 범주 l 에 속한다.
이 때, 공통 공분산 구조를 가진다면, 위와 같은 1차식이 나오며, 이는 초평면의 형태로 나타난다.

LDA의 장점
- naive bayes 모델과 달리, 설명변수간의 공분산 구조를 반영 (애초에 확률모델에서 naive bayes를 쓴다)
- 가정이 위반되더라도 어느정도 robust (변화에 민감하지 않다).
LDA의 단점
- 가장 작은 그룹의 샘플 수가 설명변수의 개수보다 많아야 함.
- 정규분포 가정에 크게 벗어난다면, 잘 설명하지 못한다.
- 공분산 구조가 서로 다른 경우를 반영하지 못한다.
Quadratic Discriminant Analysis (QDA)
LDA function vs QDA function
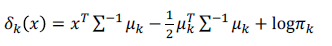

LDA의 function과 QDA의 function을 비교해보면, LDA는 1차식, QDA는 2차식이다.
LDA model vs QDA model

QDA 장점
- y 범주별로 공분산 구조를 다르게 할 수 있음. (LDA는 1차식이기에, 공분산 구조를 같을 때만 분류가 가능하다)
QDA 단점
- 설명변수의 개수가 많을수록 추정해야 하는 모수가 많아짐
- 샘플이 많이 필요하다.
'AI' 카테고리의 다른 글
| ML : 라그랑주 승수법 (Lagrange Multiplier) (0) | 2020.02.12 |
|---|---|
| ML : Model : 의사결정나무 (Decision Tree) (0) | 2020.02.12 |
| ML : Model : LDA : 사영(Projection) (0) | 2020.02.10 |
| ML : Model : LDA Math : 다변량 정규분포 (0) | 2020.02.10 |
| ML : Model : K-Nearest-Neighbor, KNN (0) | 2020.02.09 |




댓글