File input & output
MapReduce와 동일한 InputFormat, OutputFormat을 사용할 수 있다. (HDFS, Hbase, S3, Cassandra...)
File Formats
| Format Name | Structured | Comments |
| Text Files | No | 한 줄로 record 된다. |
| JSON | semi | one record per line |
| CSV | Yes | spreadsheet |
| SequenceFiles | Yes | hadoop file format, key/value data |
| Protocol buffers | Yes | fast, space-efficient multilanguage |
| Object Files | Yes | Spark Job에 의해 shared code |
text file

Text file을 input 하면, 각 line이 RDD의 element가 된다.
JSON file

JSON parser를 이용해서 text file 부르듯이 부른다.
CSV file


File Compression
Big Data 작업에서는 storage space, network overhead를 줄이는 것이 중요 -> Compression으로!


위의 Compression 들은 compression을 하더라도, Hadoop FileSystem에서 그대로 불러올 수 있게 도와준다.
Spark는 multiple different machine에서 data를 불러오기 때문에, 각각의 worker들은 data를 분산되서 받으니
서로 어디 먼저 읽는지 sync mark를 받을 필요가 있다.
서로가 어디 읽는지 sync mark를 아는 것을 splittable 하다고 한다.
그런 의미에서 splittable 한 bzip2가 압축속도는 굉장히 느리지만, text에서는 효과적으로 다룰 수 있다. 따라서 bzip2는 input을 file 그대로 가능하다.
File Systems
| Local FS | local filesystem에서도 접근 가능 |
| Amazon S3 | S3는 EC2에 위치해있다면 빠르다. id, key 있으면 가능 |
| HDFS | hdfs://path 입력하면 가능 |
| Structured Data with Spark SQL | |
| Apache Hive |  |
| JSON |  |
| Database: elasticsearch, cassandra, hbase | - |
Accumulator

옆에 코드처럼, 함수안에 지역변수와 main에 지역변수 counter들은
서로 다른 변수들이다.
따라서 지금 코드에서는 global로 전역변수로 만들어주어 해결하였다.
하지만, Spark에서는 이렇게 하면 안된다.
cluster worker를 구성하여 연산을 하기 때문에, global만 하면 local에서만 해당된다.
따라서 우리는 Accumulator 라는 새로운 방법을 도입한다.
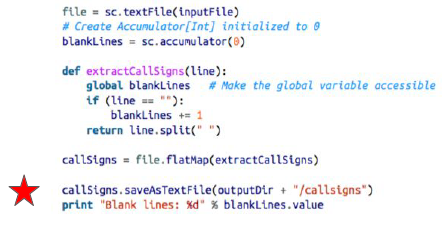
blacklines 를 cluster에서 알 수 있는 accumulator로 선언.
blacklines가 main에서도 알 수 있게 global로 만들어 준다.
worker들을 담당하며 조율하는 driver program만이 accumulator의 값을 읽을 수 있다. worker node들은 accumulator 값을 access 하지 못한다. Only Write만 가능하다.
Accumulator의 목적은 매번 update 필요없이 효과적으로 변수를 관리하기 위함이다.
'대학원 공부 > computer science' 카테고리의 다른 글
| Spark : Pair RDD (0) | 2019.12.19 |
|---|---|
| Spark : Function 예시 (0) | 2019.12.19 |
| Spark : Partitioning (0) | 2019.12.18 |
| Spark : Introduction Spark (0) | 2019.12.18 |
| Network : Transport Layer, UDP, TCP (0) | 2019.12.17 |




댓글