NLTK (Natural Language ToolKit)
NLTK 란?
nltk는 파이썬 자연어 처리 패키지로
- Classfication (분류)
- Tokenization (단어를 쪼개다)
- Stemming(형태소 분석)
- tagging (품사를 달다)
- parsing (어구를 나누다)
- semantic reasoning(의미론적 추리, 이 단어가 어떠한 의미를 가지고 있는지, 문장에서 중요한 의미인지)
이렇게 6가지를 구사할 수 있다.
tokenize
자연어 문서를 분석하기 위해서는 우선 긴 문자열을 분석을 위한 작은 단위로 나누어야 한다.
이 문자열 단위를 토큰(token)이라고 하고 이렇게 문자열을 토큰으로 나누는 작업을 토큰 생성(tokenizing)이라고 한다. 영문의 경우에는 문장, 단어 등을 토큰으로 사용하거나 정규 표현식을 쓸 수 있다.
from nltk.tokenize import sent_tokenize, word_tokenize
print(sent_tokenize(emma_raw[:1000])[3])
print(word_tokenize(emma_raw[:1000]))
"""
Sixteen years had Miss Taylor been in Mr. Woodhouse's family,
less as a governess than a friend, very fond of both daughters,
but particularly of Emma.
[ '[', 'Emma', 'by', 'Jane', 'Austen', '1816', ']', 'VOLUME', 'I', 'CHAPTER', 'I', 'Emma',
'Woodhouse', ',', 'handsome', ',', 'clever', ',', 'and', 'rich', ',', 'with', 'a', 'comfortable',
'home', 'was', 'more', 'the', 'intimacy', 'of', 'sisters', '.', 'Even', 'before', 'Miss',
-----'office', 'of', 'governess', ',', 'the', 'mildness', 'o']
"""
from nltk.tokenize import RegexpTokenizer
retokenize = RegexpTokenizer('[\w]+')
print(retokenize.tokenize(emma_raw[50:100]))
retokenize_not = RegexpTokenizer('[\W]+')
print(retokenize_not.tokenize(emma_raw[50:100]))
"""
['Emma', 'Woodhouse', 'handsome', 'clever', 'and', 'rich', 'with', 'a']
[' ', ', ', ', ', ', ', ' ', ', ', ' ']
"""- sent_tokenize : 문장을 기준으로 tokenize 한다.
- word_tokenize : 단어를 기준으로 tokenize 한다. 기호까지 다 자른다.
- RegexpTokenizer : 정규표현식으로 tuning이 가능한 tokenizer이다.
cf) '[\w]+' 이 부분은 python 정규표현식에서 word에 해당하는 부분이다.
morpheme (형태소분석)
형태소(morpheme)는 언어학에서 일정한 의미가 있는 가장 작은 말의 단위를 뜻한다.
보통 자연어 처리에서는 토큰으로 형태소를 이용한다. 형태소 분석(morphological analysis)이란 단어로부터
어근, 접두사, 접미사, 품사 등 다양한 언어적 속성을 파악하고 이를 이용하여 형태소를 찾아내거나 처리하는 작업이다.
- 어간 추출 : stemming
- 원형 복원 : lemmatizing
- 품사 부착 : part-of-speech tagging
어간 추출 (stemming)
"""
stemming : 어간추출 -> PorterStemmer, LancasterStemmer
"""
from nltk.stem import PorterStemmer, LancasterStemmer
st1 = PorterStemmer()
st2 = LancasterStemmer()
words = ['fly', 'flies', 'flying', 'flew', 'flown']
print('Porter Stemmer :' , [st1.stem(w) for w in words])
print('Lancaster Stemmer :' , [st2.stem(w) for w in words])
"""
Porter Stemmer : ['fli', 'fli', 'fli', 'flew', 'flown']
Lancaster Stemmer: ['fly', 'fli', 'fly', 'flew', 'flown']
"""어간 추출법은 단순히 어미를 제거할 뿐이지 단어의 원형을 정확히 찾아주지는 않는다.
- PorterStemmer : 어간추출, 접미사나 어미를 제거한다. 하지만 flies 경우 es만 제거 fli를 살리기 때문에 성능은 좋지않다.
- LancasterStemmer : 어간추출 : Porter보단 성능이 좋다.
원형 복원 (lemmatizing)
from nltk.stem import WordNetLemmatizer
lm = WordNetLemmatizer()
print([lm.lemmatize(w, pos='v') for w in words])
"""
['fly', 'fly', 'fly', 'fly', 'fly']
"""- lemmatizing : 원형 복원, 같은 의미를 가지는 여러 단어를 사전형으로 통일하는 작업이다. 품사를 지칭하는 경우 좀 더 정확학 원형을 찾을 수 있다.
품사 부착 (POS, part-of-speech)
품사(POS, part-of-speech)는 낱말을 문법적인 기능이나 형태, 뜻에 따라 구분한 것이다.
품사의 구분은 여러나라의 언어마다 그리고 학자마다 다르다.
예를 들어 NLTK에서는 펜 트리뱅크 태그세트(Penn Treebank Tagset)라는 것을 이용한다.
다음은 펜 트리뱅크 태그세트에서 사용하는 품사의 예 중 하나이다.
- NNP: 단수 고유명사
- VB: 동사
- VBP: 동사 현재형
- TO: to 전치사
- NN: 명사(단수형 혹은 집합형)
- DT: 관형사
nltk.help.upenn_tagset("IN") 명령으로 자세한 설명을 볼 수 있다.
"""
IN: preposition or conjunction, subordinating
astride among uppon whether out inside pro despite on by throughout
below within for towards near behind atop around if like until below
next into if beside ...
"""# pos_tag로 tagging 하기
from nltk.tag import pos_tag
sentence = "Emma refused to permit us to obtain the refuse permit"
# word_tokenize 한 것을 품사 태깅을 해서 tuple 형태를 list로 가둔다.
tagged_list = pos_tag(word_tokenize(sentence))
tagged_list
"""
VBD : 과거형동사
VBP : 현재형동사
[('Emma', 'NNP'),
('refused', 'VBD'),
('to', 'TO'),
('permit', 'VB'),
('us', 'PRP'),
('to', 'TO'),
('obtain', 'VB'),
('the', 'DT'),
('refuse', 'NN'),
('permit', 'NN')]
"""- pos_tag : word_tokenize 한 것을 품사 태깅을 해서 tuple 형태를 list로 가둔다.
Text class
NLTK의 Text 클래스는 문서 분석에 유용한 여러가지 메서드를 제공한다. 토큰열을 입력하여 생성한다.
from nltk import Text
"""
retokenize는 위에서 RegexpTokenizer 정규표현식을 이용해서 정의
plot method를 쓰면 각 단어의 사용 빈도를 그래프로 그려준다.
"""
text = Text(retokenize.tokenize(emma_raw))
text.plot(20)plot
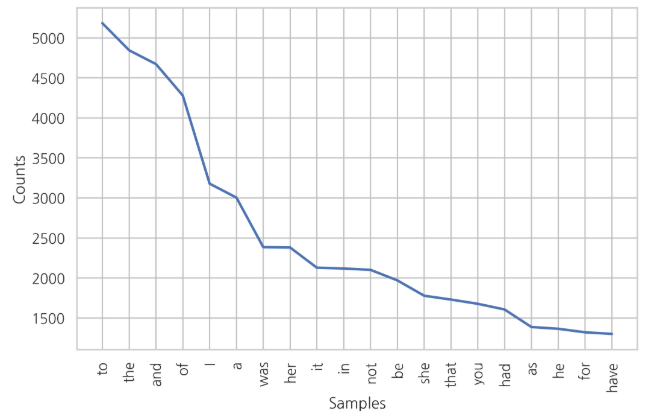
plot method를 쓰면 "각 단어의 사용 빈도"를 그래프로 그려준다. 안에 숫자는 20순위 까지를 말한다.
dispersion_plot (분산그래프)
"""
dispersion_plot method를 쓰면 단어가 사용된 위치를 시각화한다.
"""
text.dispersion_plot(["Emma", "Knightley", "Frank", "Jane", "Harriet", "Robert"])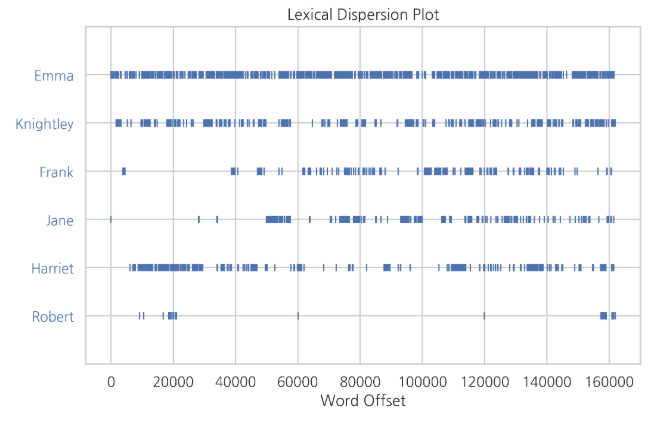
dispersion_plot method는 단어가 사용된 위치를 분산그래프로 시각화한다.
concordance
"""
concordance 메서드로 단어가 사용된 위치를 직접 표시하면 문맥(context)이 어떤지 볼 수 있다.
여기에서 문맥은 해당 단어의 앞과 뒤에 사용된 단어를 뜻한다.
"""
text.concordance("Emma")
"""
Displaying 25 of 865 matches:
Emma by Jane Austen 1816 VOLUME I CHAPTER
Jane Austen 1816 VOLUME I CHAPTER I Emma Woodhouse handsome clever and rich w
f both daughters but particularly of Emma Between _them_ it was more the intim
nd friend very mutually attached and Emma doing just what she liked highly est
by her own The real evils indeed of Emma s situation were the power of having
ding day of this beloved friend that Emma first sat in mournful thought of any
going only half a mile from them but Emma was aware that great must be the dif
a day It was a melancholy change and Emma could not but sigh over it and wish
ll the rest of her life at Hartfield Emma smiled and chatted as cheerfully as
l be able to tell her how we all are Emma spared no exertions to maintain this
or I have a great regard for you and Emma but when it comes to the question of
a fanciful troublesome creature said Emma playfully That is what you have in y
e few people who could see faults in Emma Woodhouse and the only one who ever
is was not particularly agreeable to Emma herself she knew it would be so much
being thought perfect by every body Emma knows I never flatter her said Mr Kn
that she must be a gainer Well said Emma willing to let it pass you want to h
were sure of meeting every day Dear Emma bears every thing so well said her f
l_ miss her more than she thinks for Emma turned away her head divided between
ars and smiles It is impossible that Emma should not miss such a companion sai
rgotten one matter of joy to me said Emma and a very considerable one that I m
lf than good to them by interference Emma never thinks of herself if she can d
ch better thing Invite him to dinner Emma and help him to the best of the fish
and could not think without pain of Emma s losing a single pleasure or suffer
nt of her companionableness but dear Emma was of no feeble character she was m
ent was so just and so apparent that Emma well as she knew her father was some
"""
similar
"""
similar method 는 같은 문맥에서 주어진 단어 대신 사용된 횟수가 높은 단어들을 찾는다.
즉, input한 값 대신해서 쓴 명사들을 찾는다. it she he him 등등
"""
text.similar("Emma")
common_contexts
"""
common_contexts method 는 두 단어의 공통문맥을 보는데 사용한다.
솔직히 이 부분은 잘 모르겠다...
"""
text.common_contexts(["Emma", "she"])
FreqDist
문서에 사용된 단어의 사용빈도 정보를 담는 클래스이다.
"""
FreqDist 직접 import 하는 편이 좋다.
stopword와 품사 NNP에 해당하는 부분을 제거한다. 나머지 부분을 name_list에 넣는다.
name_list를 FreqDist에 넣으면 여러가지 사용빈도 method를 쓸 수 있다.
"""
from nltk import FreqDist
stopwords = ["Mr.", "Mrs.", "Miss", "Mr", "Mrs", "Dear"]
emma_tokens = pos_tag(retokenize.tokenize(emma_raw))
name_list = [i[0] for i in emma_tokens if i[1]=='NNP' and i[0] not in stopwords]
# print(name_list)
fd_names = FreqDist(name_list)
# fd_names_fd = fd(name_list)FreqDist 직접 import 하는 편이 좋다.
stopword와 품사 NNP에 해당하는 부분을 제거한다. 나머지 부분을 name_list에 넣는다.
name_list를 FreqDist에 넣으면 여러가지 사용빈도 method를 쓸 수 있다.
# 총 단어의 갯수, Emma의 갯수, Emma가 나올 확률
print(fd_names.N(), fd_names['Emma'], fd_names.freq('Emma'))
# 가장 출현 횟수가 높은 단어
print(fd_names.most_common(5))
"""
7863 830 0.10555767518758744
[('Emma', 830), ('Harriet', 491), ('Weston', 439), ('Knightley', 389), ('Elton', 385)]
"""
참고
https://datascienceschool.net/view-notebook/8895b16a141749a9bb381007d52721c1/
Data Science School
Data Science School is an open space!
datascienceschool.net
'AI' 카테고리의 다른 글
| 자연어처리 : FastText (0) | 2020.03.04 |
|---|---|
| RL : Monte Carlo Tree Search (MCTS) (0) | 2020.02.25 |
| ML : Ensemble Learning : RandomForest (0) | 2020.02.20 |
| Statisics : Bias vs Variance (0) | 2020.02.20 |
| ML : Ensemble Learning : Bagging (0) | 2020.02.20 |



댓글