How to get document similarity?
- Cosine Similarity on Bag of Words
- Cosine similarity on <TD-IDF> with Bag of Words
Back of Words




- 먼저 문장들을 back of words를 해서 벡터로 구현한다.
- d4와의 유사도를 검증을 위해, cosine similarity를 한다. (d4는 d4와 비교하였기 때문에 유사도 1)
- 이 때, d1이 가장 비슷하다고 나왔다. 하지만 american restaurant의 메뉴가 궁금하기 때문에 search 잘못함.
- -> TD-IDF로 검증한다.
Back of Words + TF-IDF

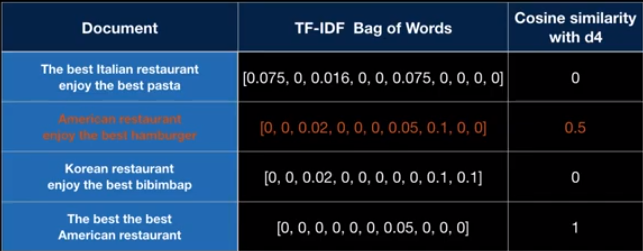
위의 table은 TF-IDF로 구현한 table이다.
Back of Words는 문장간의 반복적인 관용구들을 배제하지 못하기 때문에, Back of Words 를 진행한 후
TF-IDF로 반복적인 관용구나 필요없는 것을 버린다.
TF-IDF & Bag of Words 의 장점
- document의 유사도를 구하기 쉽고 구현하기가 쉽다.
- 관련있는 단어들의 score는 그대로 유지
- 빈도수가 높지만, 여러 문서에 존재하는 단어는 낮춘다
TF-IDF & Bag of Words 의 단점
- 단어만 보고, 그 속에 있는 유사도는 check X
- document의 topic을 아는데에는 한계가 있다.
- 다른단어인데 같은 단어의 의미를 가지는 것에 약하다 (동음이의어)
- 밑의 그림처럼 American restaurant menu, hamburger pizza는 서로 유사도가 없지만, 같은 카테고리로 유사하다.

TF-IDF & Bag of Words 을 보완해줄 방안
- LSA (Latent Semantic Analysis) : American restaurant menu, hamburger pizza 를 SVD로 서로간의 유사도 측정 -> 의미론적으로 같은 것들을 묶어준다.
- Word Embedding (Word2Vec, Glove)
- ConceptNet -> Knowledge graph를 이용, 여러가지의 단어간의 relationship을 사용 ex) Mcdonald, BurgerKing은 같은 햄버거를 다루는 레스토랑이며, 프랜차이즈이다. 이런 관계의 유사도를 측정.
TF-IDF 기반으로 t-SNE를 이용한 visualization
https://donghwa-kim.github.io/TFIDF.html
TF-IDF를 통한 변수선택과 t-SNE를 활용한 시각화
TF-IDF 순서에 상관없이 Bag-of-word 형태의 Document-Term matrix에 형태에서 중요한 단어(변수)를 선택하는 방식을 TF-IDF(Term Frequency - Inverse Document Frequency)이라고 한다. $tf_{ij}$ = number of occurences of $i$ in $j$
donghwa-kim.github.io
'AI' 카테고리의 다른 글
| 자연어 처리 : SVD 정리 (0) | 2020.03.06 |
|---|---|
| 자연어 처리 : 문서 유사도 : 유클리드, 코사인, 자카드 (0) | 2020.03.06 |
| 자연어 처리 : 카운트 기반의 단어 표현 : TF-IDF (0) | 2020.03.06 |
| 자연어 처리 : 카운트 기반의 단어 표현 : Bag of Words + DTM (0) | 2020.03.06 |
| 자연어처리 : 카운트 기반의 단어 표현 (0) | 2020.03.06 |




댓글