1. Euclidean Distance Similarity
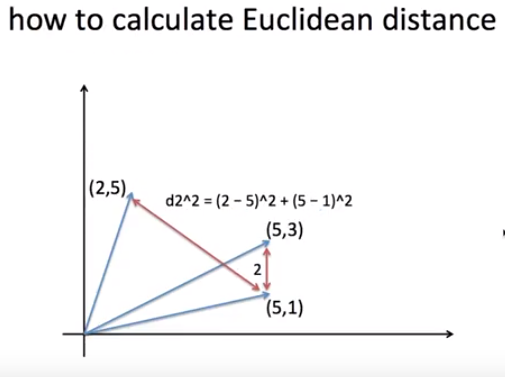
좌표를 word들이라고 가정을 해보자.
(5,1)과 다른 단어들을 유사도 측정을 해볼 때, 거리는 피타고라스 정리로 구할 수 있다.
여기서 거리가 짧으면 단어들끼리 유사도가 높고, 거리가 길면 단어들끼리 유사도가 낮다고 판단한다.
import numpy as np
def dist(x,y):
return np.sqrt(np.sum((x-y)**2))
doc1 = np.array((2,3,0,1))
doc2 = np.array((1,2,3,1))
doc3 = np.array((2,1,2,2))
docQ = np.array((1,1,0,1))
print(dist(doc1,docQ))
print(dist(doc2,docQ))
print(dist(doc3,docQ))
2.23606797749979
3.1622776601683795
2.4494897427831782. Cosine Similarity
우리는 cos을 적용하여 어느 쪽 단어에 더 가까운지, cosine을 활용하여 각도를 보고 판단한다.
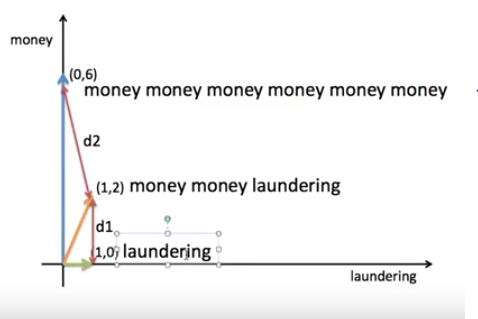
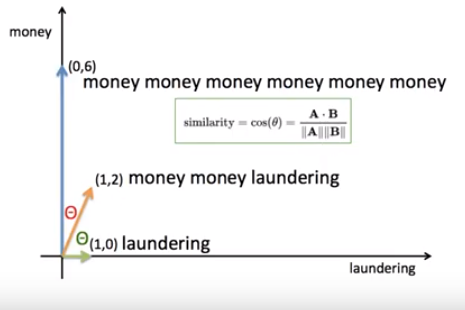
위의 첫 번째 그림처럼 x, y축을 단어들의 빈도수로 체크하였다.
거리상으로만 보면 money money laundering 은 laundering에 가깝다고 볼 수 있다.
하지만 실제로는 money money money money money money에 가깝다고 볼 수 있다.
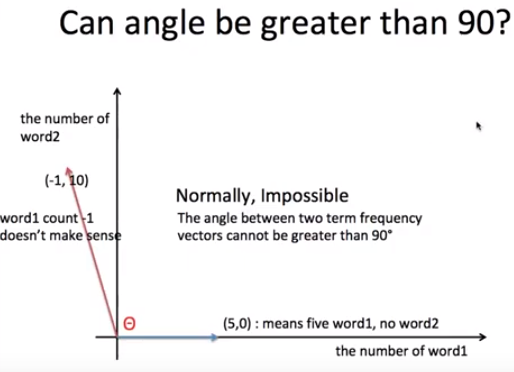
cf ) 단어의 count가 음수를 향할 수 없기 때문에, 90도를 넘길 수가 없다.
cf ) 유사도를 이용한 추천 시스템 구현하기
import pandas as pd
data = pd.read_csv('현재 movies_metadata.csv의 파일 경로', low_memory=False)
# 예를 들어 윈도우 바탕화면에 해당 파일을 위치시킨 저자의 경우
# pd.read_csv(r'C:\Users\USER\Desktop\movies_metadata.csv', low_memory=False)
data['overview'] = data['overview'].fillna('')
# overview에서 Null 값을 가진 경우에는 값 제거from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(data['overview'])
# overview에 대해서 tf-idf 수행
print(tfidf_matrix.shape)
"""
(20000,47487)
"""20,000개의 영화를 표현하기 위해, 47487 개의 단어가 사용되었다.
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
# 코사인 유사도를 구합니다.
indices = pd.Series(data.index, index=data['title']).drop_duplicates()
print(indices.head())
# 영화의 타이틀과 인덱스를 가진 테이블을 만듭니다. 이 중 5개만 출력해보도록 하겠습니다.
"""
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
dtype: int64
이 테이블의 용도는 영화의 타이틀을 입력하면 인덱스를 리턴하기 위함입니다.
"""
idx = indices['Father of the Bride Part II']
print(idx)
# 4def get_recommendations(title, cosine_sim=cosine_sim):
# 선택한 영화의 타이틀로부터 해당되는 인덱스를 받아옵니다. 이제 선택한 영화를 가지고 연산할 수 있습니다.
idx = indices[title]
# 모든 영화에 대해서 해당 영화와의 유사도를 구합니다.
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 영화들을 정렬합니다.
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 10개의 영화를 받아옵니다.
sim_scores = sim_scores[1:11]
# 가장 유사한 10개의 영화의 인덱스를 받아옵니다.
movie_indices = [i[0] for i in sim_scores]
# 가장 유사한 10개의 영화의 제목을 리턴합니다.
return data['title'].iloc[movie_indices]
#영화 다크 나이트 라이즈와 overview가 유사한 영화들을 찾아보겠습니다.
get_recommendations('The Dark Knight Rises')'AI' 카테고리의 다른 글
| ML : Machine Learning 개념과 종류 : 개념과 종류 (0) | 2020.03.07 |
|---|---|
| 자연어 처리 : SVD 정리 (0) | 2020.03.06 |
| 자연어 처리 : TF-IDF 활용해 문서의 유사도 구하기 (0) | 2020.03.06 |
| 자연어 처리 : 카운트 기반의 단어 표현 : TF-IDF (0) | 2020.03.06 |
| 자연어 처리 : 카운트 기반의 단어 표현 : Bag of Words + DTM (0) | 2020.03.06 |




댓글