정의


머신러닝은 f(x)라는 함수, 머신러닝 알고리즘을 만들어 X라는 입력변수를 받으면 Y라는 종속변수를 출력하는 과정이다.
또한 회귀분석의 경우 모집단을 잘 알지 못하기 때문에, 학습데이터만 추출하여 추정하는 머신러닝 알고리즘을 만든다.
예시

지도학습 vs 비지도학습
| 지도학습 (Supervised) | 비지도학습 (UnSupervised) |
|
Y = F(x) 일 때, Y는 연속형 변수, X는 연속 or 이산형 변수, F는 회귀모형 Y는 이산형 변수(class), X는 연속 or 이산형 변수, F는 분류모형 |
출력변수는 존재하지 않고, 입력 변수 (X) 간의 관계에 대해 모델링을 하는 것. |
| 회귀모형, 분류모형 | 군집분석(유사데이터), PCA(독립변수들의 차원축소화) |
ML의 종류
선형 회귀분석 (Linear Regression)

- 독립변수가 종속변수와 선형적인 관계 (F(x)가 존재) 할 것이라고 가정하에 분석
- 독립변수의 중요도와 영향력을 파악하기 쉬움.
의사결정나무 (Decision Tree)

- trainin data로만 training하기 때문에 input data에 너무 최적화 -> overfitting이 잘 일어난다.
- Ensemble Learning에 주로 쓴다.
SVM (Support Vector Machine)

- Class 간의 거리 (margin)가 최대가 되도록 decision boundary를 만드는 방법
- 장점 : 효율이 매우 좋다.
- 장점 : 오차를 어느정도 포함이 되게 설정이 가능. -> overfitting이 적게 일어난다.
- 단점 : training 시간이 오래 걸린다.
- 단점 : input data 많을수록 학습시간이 오래걸린다.
KNN (K-Nearest Neighbor)

- 새로 들어온 data의 주변 k개의 data의 class로 분류하는 기법
- 장점 : 굉장히 직관적이다.
- 단점 : 차원에 따라 성능이 완전 달라진다. 차원의 저주 가능성 높다.
K-means-clustering

- Label 없이 데이터의 군집으로 k개로 생성
- (b)에서 random point를 찍는다. (c)에서 random point을 이은 선과 수직하는 선을 하나 그어서 분류하고 성능을 비교, 또다시 random point를 찍고 선을 그어서 비교
Neural Network

- 입력, 은닉층, 출력층으로 구성된 모형으로써 각 층을 연결하는 Node의 weight를 업데이트하면서 학습
- 단점 : Overfitting이 굉장히 잘 일어난다.
- 단점 : 계산시간이 오래걸린다. -> GPU에 적용함으로써 해결
Ensemble Learning
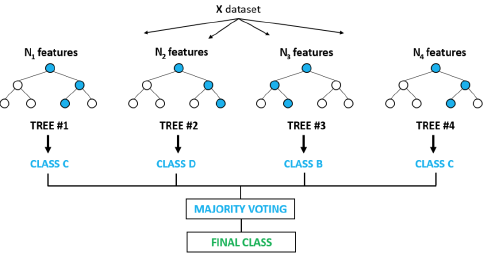
- 여러 개의 model (classifier or base learner)를 결합하여 사용하는 model
- 장점 : overfitting이 심한 model도 적용함으로써 투표하는 방식으로 인해 다양한 output들이 존재. 이로써 성능이 올라간다.
- 단점 : 여러 model을 거치니 시간이 오래걸린다.
'AI' 카테고리의 다른 글
| ML : 회귀분석 : PCA (Principal Component Analysis) 차원축소 (0) | 2020.03.07 |
|---|---|
| ML : Machine Learning 개념과 종류 : 모형의 적합성 평가 및 실험 설계 (0) | 2020.03.07 |
| 자연어 처리 : SVD 정리 (0) | 2020.03.06 |
| 자연어 처리 : 문서 유사도 : 유클리드, 코사인, 자카드 (0) | 2020.03.06 |
| 자연어 처리 : TF-IDF 활용해 문서의 유사도 구하기 (0) | 2020.03.06 |




댓글